

회전에 대한 좌표의 변환이 필요한 경우가 있어서 정리
rX = (pX-Rot_CE_X)*cos(rad) - (pY-Rot_CE_Y)*sin(rad) + Rot_CE_X;
rY = (pX-Rot_CE_X)*sin(rad) + (pY-Rot_CE_Y)*cos(rad) + Rot_CE_Y;
pX , pY : 원좌표
Rot_CE_X ,Rot_CE_Y : 회전 중심좌표

매직블럭
작은 지식들 그리고 기억 한조각
회전에 대한 좌표의 변환이 필요한 경우가 있어서 정리
rX = (pX-Rot_CE_X)*cos(rad) - (pY-Rot_CE_Y)*sin(rad) + Rot_CE_X;
rY = (pX-Rot_CE_X)*sin(rad) + (pY-Rot_CE_Y)*cos(rad) + Rot_CE_Y;
pX , pY : 원좌표
Rot_CE_X ,Rot_CE_Y : 회전 중심좌표
매직블럭
작은 지식들 그리고 기억 한조각
NLP 관련 응용 프로그램 중에서 가끔 Markov Model을 사용할 필요가 있는데, 이에 대해서 아주 잘 요약된 pt가 있어서 주석(?)을 달았다.
1. 문제의 종류 - 날씨 예측
1) 날씨(state) = { sunny, cloudy, rain }
2) 관측 데이터
3) 가정 : 오늘 날씨(current state)는 어제 날씨(previous state)에만 영향을 받는다(dependent) ==> Markov Assumption
4) 이 문제를 시각적으로 표현하면
- 각각의 상태에서 나가는 화살표(outgoing edge) 확률의 합은 1 이다.
2. 문제의 모델링 및 해결
자 이제 위와 같이 관측 데이터(observation - 과거 데이터)을 가지고 있는 상태에서, 우리는 아래와 같은 문제를 실제 풀려고 한다.
문제) sunny --> sunny --> cloudy --> rain --> sunny --> ?
물음표에는 어떤 날씨가 될 확률이 가장 높을까?
이 문제를 모델링하면 아래와 같은 그림으로 표현할 수 있다.
위의 3번째 줄에서 보면, 우리가 알고자 하는 것은 조건부 확률(conditional probability) 즉, T=t ( 현재 상태 )에서의 어떤 상태의 조건부 확률임을 알 수 있다.
그런데, 이 조건부 확률은 first-order Morkov Assumption에 의해서 바로 이전 상태에 대한 조건부 확률만 계산하면 되는 것으로 축약된다.
음.... 이건 너무 단순하잖아? 그렇다. 사실 오늘 날씨가 어떨지 계산하는 문제는 그냥 단순히 Morkov Assumption을 사용해서 계산하면 간단하다.
하지만 우리가 실제로 풀려고 하는 문제는 이것이 아니라, 좀더 복잡한 문제이다.
문제) 오늘 날씨가 sunny 인 경우, 다음 7일의 날씨 변화가(state sequence)가 'sunny-sunny-rain-rain-sunny-cloudy-sunny' 일 확률은?
에구. 사실 우리는 과거를 통해서 미래를 예측하길 원하는 거지, 단순히 오늘만을 알려고 하는 것은 아니다.
그렇다면, 이 문제의 답을 구하기 위해서 필요한 것은 무엇일까? sequence probability를 계산하는 공식이다.
이 수식을 이용해서 다시 한번 문제를 표현하면 아래와 같다.
S1 = rain , S2 = cloudy , S3 = sunny 인 경우
엥? 근데 condition으로 있는 model 은 무엇이지? 가끔 확률 공식을 보면 이런식으로 수식을 계산하는데 배경으로 깔려있는 조건 전체를 지정하기도
한다. 이는 관측 데이터에 따른 state transition probability , first-order Morkov Assumption 등등을 통칭하는 의미라고 할 수 있다.
자~ 이제 계산을 할 수 있다.
여기서 잠깐, 그런데 정말로 우리가 풀려고 하는 문제가 이것인가? 생각해 볼 필요가 있다. 다음 7일 동안의 날씨 변화(state sequence)를 아는 것은
좋은데, 우리가 진짜로 알고 싶은 것은 바로 일주일 이후 바로 그날의 날씨가 아닌가? 예를 들어, 8일째 데이트를 하려고 하는데 날씨가 어떤가?
알고 싶을 것이다.
이 문제를 풀기 위해서 또 다시 문제를 모델링하면 아래 그림과 같이 표현될 수 있다.
위 수식을 이용하면 8일째 맑을 확률을 알 수 있을 것이다. ㅎㅎ
그런데, 왜 시간 T=t에서 상태 i인 모든 path( state sequence)의 확률을 전부 더한게 T=t 에서 날씨(state)가 i 일 확률일까?
간단히 생각하면, P(A OR B) = P(A) + P(B) 이기 때문이다. ^^
3. 계산의 최적화
그런데 위의 수식을 가만히 보면, state sequence가 길어지면 질수록, state가 많아지면 많아 질수록 느려짐을 알 수 있다.
전문용어(?)로 말하면 exponential time complexity가 있다고 하는데
그냥 사용하기 느리다는 거다.
이 문제는 또 어떻게 해결해야 할까? ( 사실 Morkov Model과는 다른 문제다. 최적화 문제 )
우리의 연구자들은 이미 해결책을 찾아두셨다. ㅋㅋ
Dynamic Programming 기법을 사용하는 것인데, 이미 한번 계산한 확률은 다시 계산하지 않고 그대로 재활용하자는 개념이다.
(DP 기법은 프로그램으로 나타내면 거의 recursive callcuation이다. 고등학교때 배운 수학적 귀납법 공식을 떠올리면 쉽게 이해가 갈 것이다)
이를 수식으로 정리하면 아래와 같다.
자~~ 이제 위의 간단해진 수식을 사용하면 좀더 빨리 계산할 수 있겠다.
여기서 aji는 상태 j에서 상태 i로의 전이 확률(transition probability)이다. 즉, 모델의 prior probability 이다.
prior는 확률이론에서 아주 자주 나오는데, 그냥 우리가 이미 알고있는 사실을 기반으로 어떤 확률을 계산할 때, 그 알고있는 사실에 대해서 표현하는 단어이다.
배경지식이랄까? '동전던지기에서 앞면이 나올 확률은 0.5 이다'라는 것도 경험을 통해 얻어진 prior 라고 할 수 있다.
음... 그러면 아주 재미있는 문제를 생각해 볼 수도 있겠다.
문제)
앞면이 나오고 앞면이 나올 확률이 0.6 , 뒷면이 나올 확률이 0.4
뒷면이 나오고 뒷면이 나올 확률이 0.3, 앞면이 나올 확률이 0.7 인
조금 기형적인 동전이 있다고 하자.
여기서 상태는 { 앞면, 뒷면 }
이때, 앞으로 3번 더 던졌을 때, 그 결과가 앞면이면 내가 이길 것 같다. 그럼 그 확률은?
(단, 처음 동전을 던졌을 때, 앞면과 뒷면이 나올 확률은 같다)
이 확률을 Morkove Model를 이용해서 계산해 보자.
답) P(q3 = 앞면) = P(q2 = 앞면) * P(앞면|앞면) + P(q2 = 뒷면) * P(앞면|뒷면)
P(q1=앞면) = 0.5
P(q1=뒷면) = 0.5
P(q2 = 앞면) = P(q1 = 앞면) * P(앞면|앞면) + P(q1 = 뒷면) * P(앞면|뒷면)
= 0.5 * 0.6 + 0.5 * 0.7 = 0.3 + 0.35 = 0.65
P(q2 = 뒷면) = P(q1 = 뒷면) * P(뒷면|뒷면) + P(q1 = 앞면) * P(뒷면|앞면)
= 0.5 * 0.3 + 0.5 * 0.4 = 0.15 + 0.2 = 0.35
P(q3 = 앞면) = 0.65 * 0.6 + 0.35 * 0.7 = 0.39 + 0.245 = 0.635
오옷! 확률이 0.635나 되넹~~ ㅋㅋ 당근 걸어야쥐~~
4. 결론
Morkov Model에 대해서 이해하는 데 있어, 핵심은 바로
"우리는 과거를 통해서 미래를 알고 싶다" 일 것이다.
그리고 가끔 Hidden Morkov Model과 헷갈리는 응용이 있는데, 이를 구분하는 방법은 미래 상태(state)를 관측할 수 있는가에 달려있다.
예를 들어, part-of-speech tagging 에서는 상태가 바로 품사(POS)이다. 그런데 우리는 아래와 같은 문제에서 품사는 관측 못하고 품사에서
생성된(generated) 형태소만을 알 수 있다.
문제) '나는 학교에 간다' 라는 문장을 태깅하시오.
그래서 HMM에서는 emition probability 혹은 generation probability 라는 개념이 추가적으로 들어간다.
5. 마지막으로, Markov Model을 가지고 응용할 수 있는 문제들은 어떤게 있을까?
음... 예를 들자면, 전국민의 놀이 로또(lotto)가 있을 수 있겠다.
로또의 경우는
관측 가능한 상태 = { 1, 2, ....., 45 }
초기 prior 확률은 현재 297회까지 진행되었으니, 이를 통해서 구할 수 있을 것이다.
따라서, 6개의 번호에 대해서 선택한 경우, 이 sequence의 확률을 계산할 수 있겠다.
45개에서 6개를 순서있게 선택하는 경우의 수를 45P6 인데, 이 모든 경우에 대해서 sequence probability를 구해서
가장 확률이 높은 순서열을 구한다면 어떨까?
요새 웹에 떠돌아 다니는 로또 번호 자동 생성기는 아마도 이걸 응용한 프로그램이라고 생각된다. 혹시 다른 방법을
사용했을 수도... ㅋㅋ
관심있는 분은 만들어 보시길~~ ^^
아 참고로, 유전자 알고리즘(genetic algorithm)을 이용해서 로또 생성기를 만드는 경우도 있을 겁니다.
짧게 설명하면, 유전자 알고리즘은 아래 그림(참조 URL)과 같이 설명될 수 있는데,
여기서 population 부분은 feature vector로 일종의 유전 형질이라고 할 수 있다. 좋은 유전 인자는 계속 유전되고, 그렇지 않은 열성 인자는 자연 도태된다.
세대를 거치면 거칠 수록 말이다. selection, cross-over, mutation 등의 기본 연산은 자연의 유전 법칙을 시뮬레이션 한 것이라 할 수 있다.
로또의 경우는 279회차 까지의 당첨 번호를 가지고 길이가 45인 279개의 feature vector를 만들어 낼 수도 있을 것이다.
해당 회차에 당첨된 번호는 우성 번호이고, 그렇지 않은 번호는 열성 번호로....
이를 이용해서 유전자 알고리즘을 수행하고 몇 세대 이후 남아있는 feature vector를 decoding해서 적절하게 원하는 번호를 선택하는 방법입니다.
이 방법과 Markov Model을 결합해서 hybird로 만들어 볼 수도 있겠군요. ㅋㅋ
물론, 학술적인 연구와는 거리가 있고 그냥 단순히 '재미로'겠지만 말입니다. ^^
[출처] KISS ILVB Tutorial(한국정보과학회) 에서 발표( Dr. Sung-Jung Cho)된 내용 중 발췌
[2차출처] http://blog.daum.net/hazzling/15605818
Markov Model 의 개념이 잘 정리된 것 같아서 스크랩.
| 대표적인 Discrete Random Variable (0) | 2014.04.09 |
|---|---|
| 기본 함수의 개념 (0) | 2014.04.09 |
매직블럭
작은 지식들 그리고 기억 한조각
매직블럭
작은 지식들 그리고 기억 한조각
CDF ( Cumulative Distribution Function ) - 누적분포함수
어떤 확률 분포에 대해서, 확률 변수가 특정 값보다 작거나 같은 확률을 나타낸다.
일정 범위 사이에 R.V 가 속할 확률은 두 CDF 의 차로 계산 할 수 있다.
특정한 값 x에서의 확률은 아래와 같이 계산 가능하다.
PDF ( Probability Density Function ) - 확률밀도함수
continuous 한 random variable 에 의한 확률분포함수를 의미한다.
분포 내에는 무수히 많은 값을 가지므로 특정한 한 값에서의 확률은 0으로 수렴한다.
확률밀도함수는 아래의 두가지 조건을 성립해야 한다.
첫째는 항상 양의 값을 가져야 한다는 것.
둘째는 모든 범위의 pdf를 합하면 그합은 1이 된다는것.
범위가 존재하지 않는다면 확률은 존재 하지 않고 정의된 범위 내에서의 확률은
범위내의 pdf 영역의 넓이(적분값) 가 된다.
PMF ( Probability Mass Function ) - 확률질량함수
pdf와 반대로 discrete 한 random variable 에 의한 확률분포함수를 의미한다.
pmf 는 각 요소들이 실제 확률을 의미한다. 왜냐하면, 딱 그 경우에 대한 확률도 정확히 표현 가능하니까..
CDF를 미분하면 PDF / 반대로 PDF 를 적분하면 CDF 가 된다.
| Markov Process (0) | 2014.06.13 |
|---|---|
| 대표적인 Discrete Random Variable (0) | 2014.04.09 |
매직블럭
작은 지식들 그리고 기억 한조각
A가 계수(rank) k인 ![]() 행렬이면, A는
행렬이면, A는
![]() (3)
(3)
와 같이 인수분해될 수 있다. 여기서 P는 계수가 k인 ![]() 양의 반정부호행렬이고, Q는
양의 반정부호행렬이고, Q는 ![]() 직교행렬이다. 더욱이 만일 A가 가역행렬(계수 n)이면, P는 양의 정부호행렬인 (3)형의 인수분해가 존재한다.
직교행렬이다. 더욱이 만일 A가 가역행렬(계수 n)이면, P는 양의 정부호행렬인 (3)형의 인수분해가 존재한다.
A의 특이값분해를
![]()
와 같이 고쳐쓰면 행렬 ![]() 는 직교행렬의 곱이므로 직교행렬이다. 그리고 행렬
는 직교행렬의 곱이므로 직교행렬이다. 그리고 행렬 ![]() 는 대칭행렬이다. 또한 행렬 Σ와
는 대칭행렬이다. 또한 행렬 Σ와 ![]() 는 서로 직교적으로 닮았으므로, 그들의 계수와 고유값은 같다. 따라서 P의 계수는 k가 되고 그것의 고유값은 음이 아니다(이것은 Σ에 대해서 성립하므로). 따라서 P는 계수가 k인 양의 반정부호행렬이 된다. 더욱이 만일 A가 가역행렬이면, Σ의 대각선위에는 영이 존재하지 않는다. 따라서 P의 고유값은 양의 실수이고 P는 양의 정부호행렬이 된다.
는 서로 직교적으로 닮았으므로, 그들의 계수와 고유값은 같다. 따라서 P의 계수는 k가 되고 그것의 고유값은 음이 아니다(이것은 Σ에 대해서 성립하므로). 따라서 P는 계수가 k인 양의 반정부호행렬이 된다. 더욱이 만일 A가 가역행렬이면, Σ의 대각선위에는 영이 존재하지 않는다. 따라서 P의 고유값은 양의 실수이고 P는 양의 정부호행렬이 된다.
여기서 행렬 P는 변형의 확장과 압축효과(scaling)을 나타내고, 행렬 Q는 비틀림(반사와 함께)을 나타낸다.
행렬
![]()
의 극분해를 구해보자. 행렬 A를 특이값분해하면
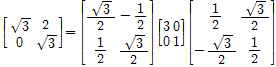
이 되므로
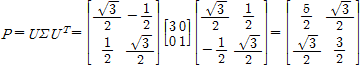
과
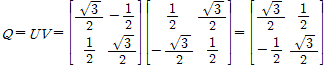
을 얻는다. 따라서 A의 극분해는
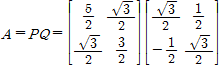
이 된다. 어떤 변수 x가 A에 의해 곱해진다는 것은 Q가 곱해지고 P가 곱해지는 것을 의미하는데, Q는 직교행렬이고
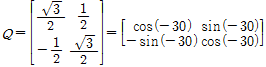
과 같다. 이는 원점에 대한 회전을 의미하며 P의 경우, 회전된 두 개의 열벡터를 ![]() 의 단위고유벡터
의 단위고유벡터 ![]() 의 방향으로
의 방향으로 ![]() 배 확장하고
배 확장하고 ![]() 의 방향으로
의 방향으로 ![]() 배 확장하는 것을 뜻한다.
배 확장하는 것을 뜻한다.
[출처] 극분해(Polar Decomposition)|작성자 JamesKim
| positive definite / negative definite / indefinite (0) | 2013.10.16 |
|---|
매직블럭
작은 지식들 그리고 기억 한조각
이차형식 ![]() 는
는
모든 ![]() 에 대하여
에 대하여 ![]() 이면 양의 정부호(positive definite),
이면 양의 정부호(positive definite),
모든 ![]() 에 대하여
에 대하여 ![]() 이면 음의 정부호(negative definite),
이면 음의 정부호(negative definite),
x에 따라서 ![]() 가 양과 음의 값을 가지면 부정부호(indefinite)라고 한다.
가 양과 음의 값을 가지면 부정부호(indefinite)라고 한다.
이 정의의 용어는 행렬 A에도 적용된다. 즉 대칭행렬 A는 관련된 이차형식 ![]() 가 갖는 위의 조건에 따라 양의 정부호, 음의 정부호, 또는 부정부호라고 한다.
가 갖는 위의 조건에 따라 양의 정부호, 음의 정부호, 또는 부정부호라고 한다.
다음 정리는 행렬 A와 이에 의한 이차형식 ![]() 가 양의 정부호, 음의 정부호, 또는 부정부호인지 결정할 때 고유값을 사용하는 방법을 제공한다.
가 양의 정부호, 음의 정부호, 또는 부정부호인지 결정할 때 고유값을 사용하는 방법을 제공한다.
(정리) A가 대칭행렬일 때
(a) ![]() 가 양의 정부호이기 위한 필요충분조건은 A의 모든 고유값이 양의 실수인 것이다.
가 양의 정부호이기 위한 필요충분조건은 A의 모든 고유값이 양의 실수인 것이다.
(b) ![]() 가 음의 정부호이기 위한 필요충분조건은 A의 모든 고유값이 음의 실수인 것이다.
가 음의 정부호이기 위한 필요충분조건은 A의 모든 고유값이 음의 실수인 것이다.
(c) ![]() 가 부정부호기이 위한 필요충분조건은 A가 적어도 하나의 양의 고유값과 적어도 하나의 음의 고유값을 갖는 것이다.
가 부정부호기이 위한 필요충분조건은 A가 적어도 하나의 양의 고유값과 적어도 하나의 음의 고유값을 갖는 것이다.
(a)와 (b)의 증명 주축정리에 의하여
![]() (2)
(2)
을 만족시키는 직교변수변환 x=Py가 존재한다. 더욱이 P의 가역성에 의하여 ![]() 이기 위한 필요충분조건은
이기 위한 필요충분조건은 ![]() 이므로,
이므로, ![]() 에 대한
에 대한 ![]() 의 값은
의 값은 ![]() 에 대한
에 대한 ![]() 의 값과 같다. 따라서 (1)에 의하여
의 값과 같다. 따라서 (1)에 의하여 ![]() 에 대하여
에 대하여 ![]() 이기 위한 필요충분조건은 방정식 (2)의 모든 λ(A의 고유값)가 양의 실수인 것이고,
이기 위한 필요충분조건은 방정식 (2)의 모든 λ(A의 고유값)가 양의 실수인 것이고, ![]() 에 대하여
에 대하여 ![]() 이기 위한 필요충분조건은 모든 고유값이 음의 실수인 것이다. 이로써 (a)와 (b)가 증명되었다.
이기 위한 필요충분조건은 모든 고유값이 음의 실수인 것이다. 이로써 (a)와 (b)가 증명되었다.
[출처] 극분해(Polar Decomposition)|작성자 JamesKim
| Polar decomposition (0) | 2013.10.16 |
|---|
매직블럭
작은 지식들 그리고 기억 한조각









